Data-based medicine might sound like a better way to treat patients. The advances in collecting information, especially sequencing genes, promise to push physicians closer to improved patient care. Even more, the combination of information on a patient’s genes (genotype) and traits (phenotype) could be combined to make smarter decisions on clinical options. This information could be used in pharmacogenomics, which explores how a patient’s genes impact their reaction to a drug. But, is medicine making full use of this information?

The short answer is: not quite yet. As Cyrine Haidar, clinical pharmacogenomics coordinator at St. Jude Children’s Research Hospital, Memphis, TN, said: “At this time, combining genotype and phenotype data to advise patient treatment is not a common practice but is slowly gaining acceptance.”
Other experts agree. As an example, Julie England, chief medical officer at Minneapolis-based OneOme added: “Pharmacogenomics remains an emerging science, and we’re still at the early end of the adoption curve. We have a significant body of evidence showing the analytical and clinical validity of pharmacogenomics, so our current focus is on advancing clinical utility and provider adoption.”
Even as this technology remains immature, the pharmacogenomic market appears on the rise. A 2019 report from BIS Research forecast that the $4.49 billion market in 2018 will grow to more than $8.98 billion by 2028. That’s a big jump, and the technology and techniques need to move ahead to meet that vision.
Even a broad look at research suggests growth in this field. A search of genotype, phenotype, and medicine on PubMed revealed an increasing number of publications including that trio of terms—especially in the past few years. For example, articles emerging from this search strategy increased from just over 800 in 2007 to nearly 3,200 in 2017. So, in just a decade, the published articles in this area—based on a very general assessment—climbed by a factor of four. As interest and opportunities accelerate the combination of genotype and phenotype on clinical care, even more research is likely. That will create a cycle that could advance the use of these data in healthcare in the next decade.
Relying on records
At OneOme, England and her colleagues are taking two approaches to making pharmacogenomic information more available. One is integrating electronic health records (EHRs) with what England calls clinical decision–support alerts. “This intuitive technology platform allows clinical experts at each health system to write and set alerts for specific phenotype-medication combinations,” she said. “This gives providers throughout the organization valuable information at the point of prescribing.”
The second approach at OneOme is its stratification engine. “Testing every single patient isn’t practical for most institutions, and our solution can help identify patients most likely to benefit from pharmacogenomic testing,” England noted. “This tool uses de-identified patient health history information—typically using a patient or member number to tie results back to individual patients—to generate a report that stratifies the population into tiers based on the likelihood for medication changes and improved outcomes with pharmacogenomic testing.”
It’s a bit early to determine the efficacy of the EHR-related approach, but OneOme has some preliminary data on its stratification engine—particularly on its reliability in identifying the patients most likely to benefit from pharmacogenomic testing. “In a population of just under 20,000, we found that the individuals who we identified as having the highest likelihood of benefiting from pharmacogenomic testing had, on average, 61% higher prescription spend and 130% higher total cost of care than the next tier, based on insurance claims data,” England says. “In a separate study of 100,000 lives, the OneOme stratification engine was statistically significant in predicting future total cost of care.”
As discussed below, other studies also explore the benefits of EHRs. Work like that being done at OneOme and in other companies and organizations shows the foundational need for data in this area. The better the data—and probably more of it—the better the results.
Existing applications
In some cases, clinicians already put genetic information to work. One example involves thiopurine methyltransferase (TPMT). This enzyme metabolizes thiopurines, which are used to treat various immune-related diseases and some blood-related diseases, including leukemia. Haidar calls this an example “where combining genotype data and phenotypic data has been used to improve medication selection and dosing in a personalized setting.”

Here, a patient can be tested for variants in the TPMT gene and activity levels of the enzyme. Getting the complete picture for a patient requires both the genotype and phenotype test. “Because genotyping platforms tend to interrogate the most commonly known variants for a specific gene, phenotyping assays are used whenever available to help supplement the genetic test result—as is the case with TPMT phenotyping,” Haidar explained. “Utilizing phenotype testing in conjunction with genotype testing allows for the identification of patients who may have rare inactivating variants that are not interrogated by the genotype platform.”
Still, even the combination of testing can suffer from potential flaws. “Just like any laboratory-developed test, phenotype—activity—testing also has its limitations,” Haidar pointed out. “For example, TPMT activity tests may provide false normal activity levels in patients who have recently received a blood transfusion.”
Haidar and her colleagues also test for an enzyme called glucose-6-phosphate dehydrogenase (G6PD). “Patients who are heterozygous—with one normal and one deficient allele—for G6PD cannot be assigned a definite phenotype from G6PD genotyping,” she explained. “The recommendation is to perform a G6PD activity test on all heterozygous patients to assign G6PD activity in such individuals.” Someone with low G6PD activity who is prescribed rasburicase, which can remove uric acid from the blood, can end up with severe hemolytic anemia, because the red cells get destroyed. Although data on this remains limited, Haidar said that one patient at St. Jude tested normal for G6PD activity but experienced hemolysis after taking rasburicase. In fact, this patient required “multiple blood transfusions and supportive care management of that episode.” Later, the G6PD genotyping showed that the patient was homozygous for a G6PD-deficient allele. “She had received blood transfusions prior to being treated at St. Jude, which falsely elevated her G6PD activity result into the ‘normal’ range,” Haidar said.
Varying approaches

Scientists can use genotype and phenotype data in various ways. At the University of Florida in Gainesville, for example, pharmacotherapy expert Larisa Cavallari said: “We do not combine genotype and phenotype data in most instances, but rather assign phenotype based on genotype results, with consideration of relevant drug interactions.”
As an example, consider a cytochrome P450 enzyme, like CYP2D6, that plays a role in metabolizing many drugs. A patient could have a CYP2D6 genotype associated with normal metabolism but is taking a strong CYP2D6 inhibitor, which converts the patient to a poor metabolizer relative to this enzyme.
In one study, Cavallari and colleagues examined the impact of using the CYP2D6 phenotype—assigned based on genotype and drug interactions—to guide opioid therapy. When asked about the biggest clinical benefit from this work, Cavallari said: “First, the results demonstrate the feasibility of implementing genotyping into clinical practice to guide management of chronic pain. Secondly, the findings suggest that a genotype-guided approach to pain management can lead to better pain control.”
This will be examined more thoroughly in an upcoming clinical trial funded by the National Human Genome Research Institute as part of the Implementing GeNomics In pracTicE (IGNITE) Network, she said.
A question of value
In many studies of combining genotype and phenotype data, healthcare experts wonder about the benefits. So, Catherine Chanfreau-Coffinier, a research health scientist at the Veteran’s Administration Informatics and Computing Infrastructure in Salt Lake City, and her colleagues took one approach to that topic.

Using the frequencies of gene variants from the 1000 Genomes Project and 7.7 million U.S. veterans who had used the Veterans Health Administration pharmacy services, Chanfreau-Coffinier and her colleagues estimated how many might have a gene-drug interaction. The computations indicated that 99% of the veterans probably have at least one variant that could impact a drug response.
This is not a straightforward conclusion. “We work with complex information,” Chanfreau-Coffinier said. “There are multiple genes and each has variants that could be a loss or a gain of function.” Plus, these variants are not rare, and combinations can create the drug interaction. “One gene can impact multiple drugs,” Chanfreau-Coffinier noted.
Here, Chanfreau-Coffinier and her colleagues worked with data on gene variants and the drugs prescribed to the veterans. “Having phenotype information would help,” she said, “because phenotype can be specific to one gene-drug pair,” and sometimes more than one gene. As an example, the effect of the blood-thinner warfarin is related to several genes, Chanfreau-Coffinier noted. Digging deeper requires more studies. (See page 20, “A New PHASER”)
Calculating breast cancer risk
One company already packs lots of genotype and phenotype information into one metric. That’s the myRisk with riskScore test, which provides “actionable risk information for breast cancer,” said Jerry Lanchbury, chief scientific officer at Myriad Genetics based in Salt Lake City. This score arises from information on 11 breast cancer genes, plus a wide range of phenotype data, from body-mass index and family history to age at menarche and menopause.
For the roughly 90% of women who do not have a mutation in a high-risk gene for breast cancer, like BRCA1 or BRCA 2, the polygenic risk-Score provides additional information on 86 genetic markers, called single nucleotide polymorphisms (SNPs), that when combined with clinical risk factors can be used to predict a woman’s five-year and lifetime risk of developing breast cancer. If the lifetime risk is above 20%, then the woman is a candidate for special care, such as MRI monitoring instead of mammograms, because MRI catches breast cancer earlier.
“About 60% of our business is unaffected women who have no tumor, so you’re looking at germline DNA to assess their risk of getting cancer,” Lanchbury said.
“When a tumor is present, germline DNA may help us understand the cause of cancer, risk of secondary cancers and which therapies might be most beneficial. However, RNA can be even more useful to assess cancer aggressiveness and whether more or less treatment is needed.” (See: RNA-Based Risk.)
Creating a code
In addition to the VA, some other organizations collect genotype and sequence data on large groups. That’s what Geisinger is doing with its MyCode Community Health Initiative, which performs exome sequencing and genotyping on participants in this clinical research project. So far, more than 250,000 Geisinger patients have consented to participate.
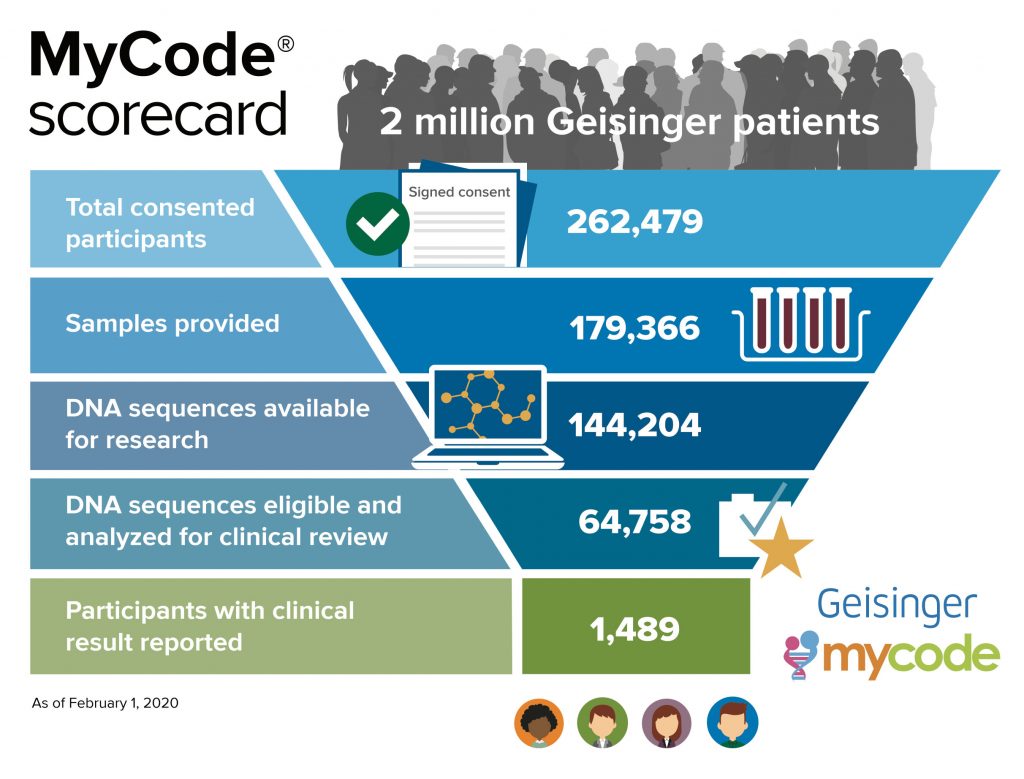
“We analyze the sequence and look for disease-causing or likely disease-causing variants in the genes that we define as clinically actionable,” said Marc Williams, physician and director of the Geisinger Genomic Medicine Institute. “Then, we look at clinical data from those people and combine all of that to develop a personalized plan of care with the intent to improve outcomes.” Early analysis of the impact of returning pathogenic or likely pathogenic variants has identified that most participants who have one of these variants had not had prior clinical testing, so the people could not have taken advantage of interventions to improve care. This surveillance—recommended based on the genetic variants—has led to the discovery of early stage cancer and other diseases in some participants.
This combination of gene- and clinical-based information is used to help the participating patients and sometimes their relatives. “We use individual information to expand the impact to other family members who might be at risk,” Williams explained. “We’ve arranged testing in hundreds of relatives where we’ve confirmed the presence or absence of a variant.”
The collection of data—sequencing genes and finding phenotypes—makes it possible to approach medical decisions with more knowledge than ever before. Yet, as Williams said of this area, “it’s early days.” It’s early days in collecting the data, and maybe even earlier in learning how to use it. The successes so far, though, encourage those in healthcare that combinations of data from genotypes and phenotypes will change medicine in the future, and perhaps even sooner than we think.
A New PHASER